1. YOLOv8模型的模型转换
a. 模型转换第一步:Parser
如何选取模型的end node。需要注意的是,Hailo比较擅长的是AI推理部分,其实对后处理方面,特别是NMS部分,没有那么擅长。对于YOLOv8模型的后处理部分,可能不能支持到比较常见的模型concat节点(/model.22/Concat_5)。我们推荐使用model zoo里面提到的节点:
- /model.22/cv2.0/cv2.0.2/Conv
- /model.22/cv3.0/cv3.0.2/Conv
- /model.22/cv2.1/cv2.1.2/Conv
- /model.22/cv3.1/cv3.1.2/Conv
- /model.22/cv2.2/cv2.2.2/Conv
- /model.22/cv3.2/cv3.2.2/Conv
参考链接: YOLOv8s YAML配置
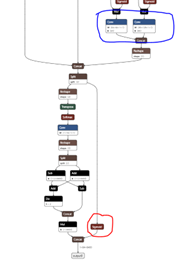
如图中蓝色部分(其中两个节点)
b. 模型转换第二步:optimization(量化时使用的脚本alls)
可以参考 YOLOv8s 量化脚本:
normalization1 = normalization([0.0, 0.0, 0.0], [255.0, 255.0, 255.0])
change_output_activation(conv42, sigmoid)
change_output_activation(conv53, sigmoid)
change_output_activation(conv63, sigmoid)
nms_postprocess("../../postprocess_config/yolov8s_nms_config.json", meta_arch=yolov8, engine=cpu)第一行为正常的将归一化放在Hailo进行处理。
第二到第四行为在节点末尾增加sigmoid。
增加sigmoid的原因是类似YOLOv5的模型,对于类别的score,需要进行sigmoid运算,可以将这部分放到Hailo中进行。如图1中的红色框部分。
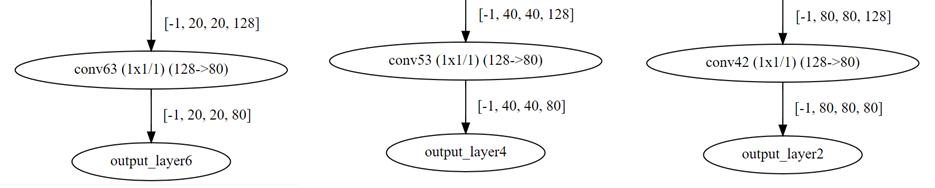
如何确定 conv42, conv53, conv63 这三个节点而不是其他节点:
在第一步parser以后,可以通过DFC命令:hailo visualizer yolov8s.har 得到第一步解析后模型的架构图: yolov8s.svg。因为我们的end node是6个节点,所以应该有6个output_layer,注意查看class类别的output_layer上一个conv(我这里使用的是COCO标准80个类别的模型)。
第5行是后处理脚本,使用的是model zoo里面的 yolov8s_nms_config.json 脚本。这是为了客户做YOLOv8的后处理,Hailo将这部分后处理封装在Hailort的API中,只需要在编译模型的时候加上第5行,在Hailort推理的时候,Hailort的SDK会自行在host端运行必要的后处理程序,方便客户直接得到NMS后的输出结果。特别注意针对自己的模型修改文件 yolov8s_nms_config.json。
{
"nms_scores_th": 0.2,
"nms_iou_th": 0.7,
"image_dims": [
640,
640
],
"max_proposals_per_class": 100,
"classes": 80,
"regression_length": 16,
"background_removal": false,
"background_removal_index": 0,
"bbox_decoders": [
{
"name": "bbox_decoder41",
"stride": 8,
"reg_layer": "conv41",
"cls_layer": "conv42"
},
{
"name": "bbox_decoder52",
"stride": 16,
"reg_layer": "conv52",
"cls_layer": "conv53"
},
{
"name": "bbox_decoder62",
"stride": 32,
"reg_layer": "conv62",
"cls_layer": "conv63"
}
]
}特别要注意这里的 class num 以及不同的节点的替换(特别是自行训练或者略微修改的YOLOv8模型)。
reg_layer 对应的就是 image_dims / stride 的regression. 例如:20x20x64 / 40x40x64 / 80x80x64。
c. 模型转换第三步Compilition(编译模型成HEF)
只需要注意下编译完成的HEF使用命令 hailortcli parse-hef yolov8s.hef 查看下结果。

在转换模型的步骤“模型转换第二步量化时使用的脚本alls”中,在alls中增加一行:
performance_param(compiler_optimization_level=max)此方法会极大地增加编译模型成HEF的编译时间,但是可以提高hef在hailo中的运行FPS, 请知悉。详情可以参考Hailo的Data Flower Compiler文档。
2. YOLOv8模型的推理 (C++)
这里推荐使用这个GitHub: NpuDetectorLib,里面有针对类似这样转化的YOLOv8_nms模型的样例:
./build/tests/TestExecutable -i VID.mp4 -o VID_out.mp4 -m models/yolov8s_nms.json -a base我们只需要替换对应的 yolov8s_nms.json(YOLOv8s NMS JSON)为我们自己的JSON就可以了。注意修改以下内容:
"model_path": "models/yolov8s_nms.hef""classes": 80"labels": ["__background__"]"threshold": 0.5"output_order_by_name": ["yolov8s/yolov8_nms_postprocess"]
3. 某些特殊情况说明
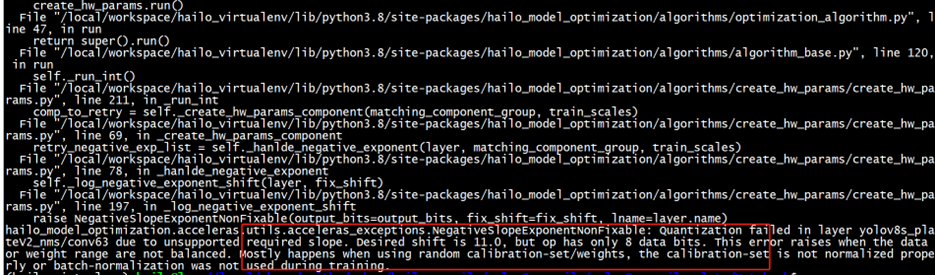
某些时候,客户使用自己的数据库训练的YOLOv8模型,按照上述方式进行模型转换的时候,可能会遇到类似这样的报错:
{kind=link}
当出现类似这种报错的时候,可以在上述“b.模型转换第二步量化时使用的脚本alls”中,仅使用Hailo进行归一化:
normalization1 = normalization([0.0, 0.0, 0.0], [255.0, 255.0, 255.0])查看是否能正常编译通过。一般情况下,这样是可以编译通过的。
针对此特定模型,如何对模型进行推理?
首先,利用 hailortcli parse-hef yolov8s.hef 可以得到类似以下的输出:
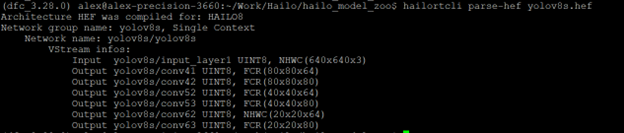
此模型与上面的NMS模型有两个区别:
- 此模型没有在Hailo中加入任何后处理,所以需要在集成代码中自行增加后处理的代码(包括NMS部分)。
- 此模型没有对score部分在Hailo内部做sigmoid操作,因此需要在集成代码中加入sigmoid。
参考上面的demo,注意修改JSON文件:yolov8s.json
"model_path": "models/yolov8s.hef","classes": 80,"feature_map_size": [80, 40, 20],"labels": ["__background__"],"output_order_by_name": ["yolov8s/conv41"],"out_sigmoid": false
需要注意的是,"output_order_by_name" 对应的节点序号需要与 feature_map_size 的对应。此外,由于需要进行sigmoid操作,所以 "out_sigmoid" 需要设置为 false。
具体推理命令使用:
./build/tests/TestExecutable -i 2.jpg -m models/yolov8s.json -a yolov8
发表回复