CLIP(Connecting text and images)是一个由OpenAI开发的模型,可以将图片与文字进行对应。其基本原理是通过transformer将图片和文字分别进行编码,然后通过对比两种编码的相似度,将图片与文字的关系对应起来。
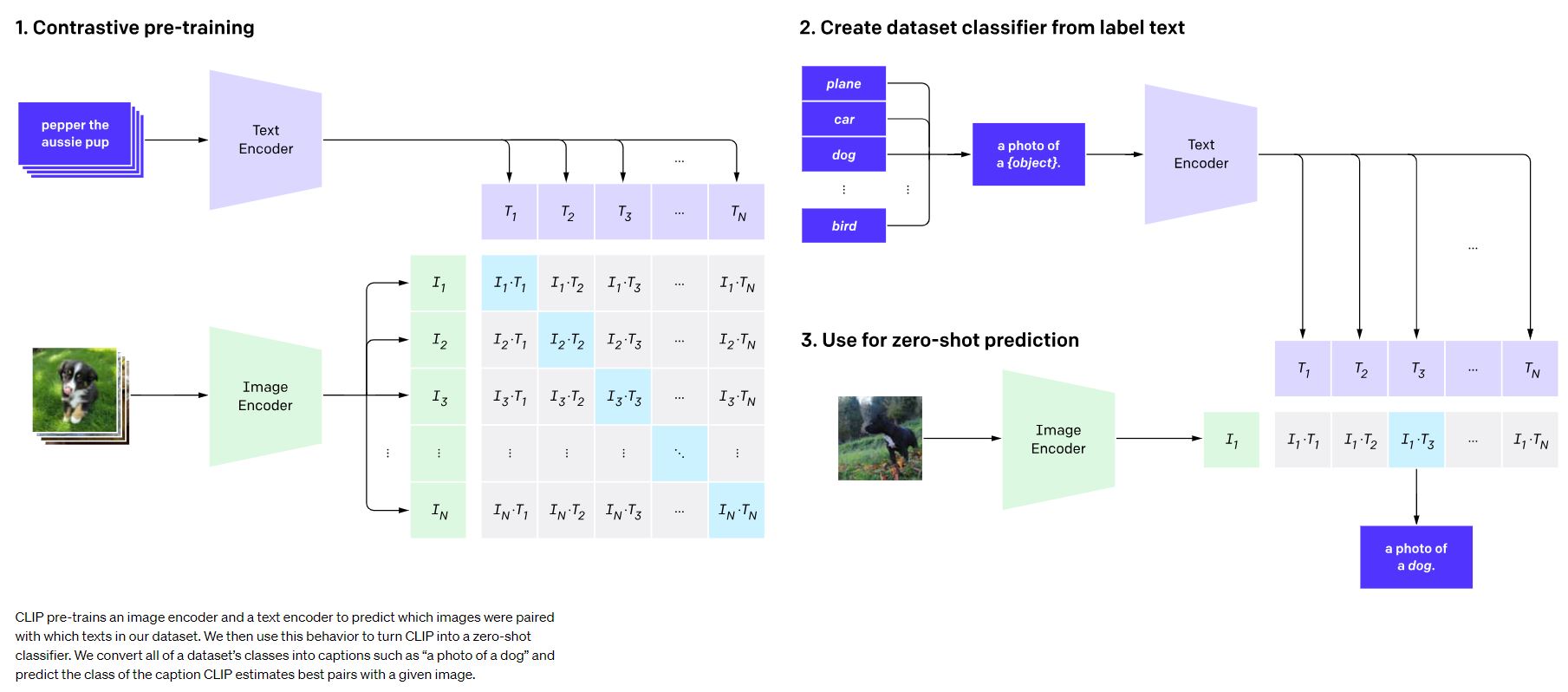
在VMS(Video Management System)中,我们可以利用CLIP模型实现一些特定的功能。例如,我们可以将需要识别的人员图像从原始图像中抠出,然后利用CLIP对这些人员图像进行编码。这样,我们就可以得到每个人员的特定编码。接着,我们可以将这些编码与预先处理的文字编码进行对比,找到最相似的文本(例如:找到所有带帽子的人, 或者穿着蓝色衣服的人),从而实现一些特殊情况的预警处理。
另一个应用方向是,如果我们希望在系统重重点关注某个特定的人,我们可以将这个人的图像抠出并进行编码(A)。然后,在系统中的其他摄像头下,针对所有人进行编码,并将这些编码与A的编码进行对比。通过这种方式,我们可以实现对特定人员的重点监控。
总的来说,CLIP模型在VMS中的应用可以帮助我们更好地利用图像和文字之间的关系,从而实现更智能和更高效的视频管理系统。
发表回复