BlendMask 模型架构与特点
BlendMask 模型架构: 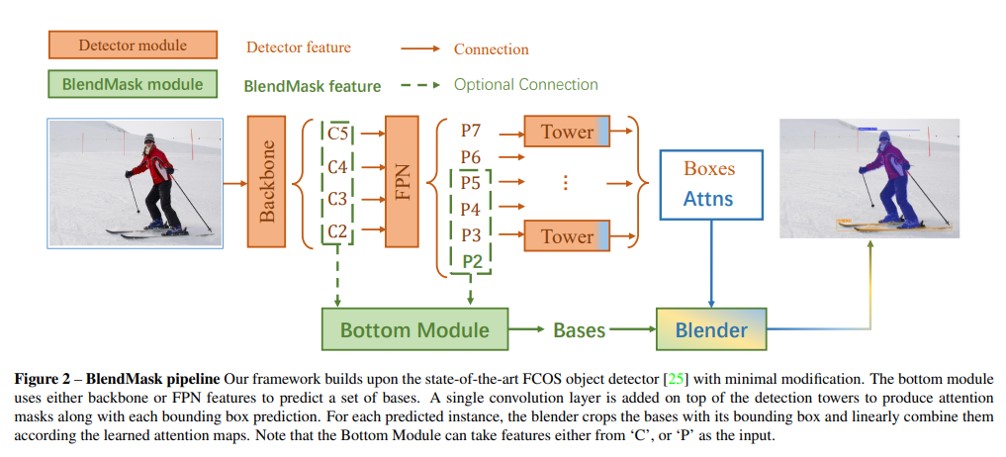
-
主干网络(Backbone):
BlendMask 使用一种强大的主干网络,通常采用现代的卷积神经网络(CNN)结构,如 ResNet 或者 ResNeXt。主干网络负责从输入图像中提取高级别的特征。
-
FPN(Feature Pyramid Network):
引入特征金字塔网络(FPN),用于处理不同尺度上的目标。FPN 提高了模型对于不同大小目标的感知能力,并促进了准确的实例分割。
-
Context Module:
BlendMask 引入上下文模块,用于捕捉目标实例周围的上下文信息。这有助于提高实例分割的语境感知能力,使模型更好地理解目标的环境。
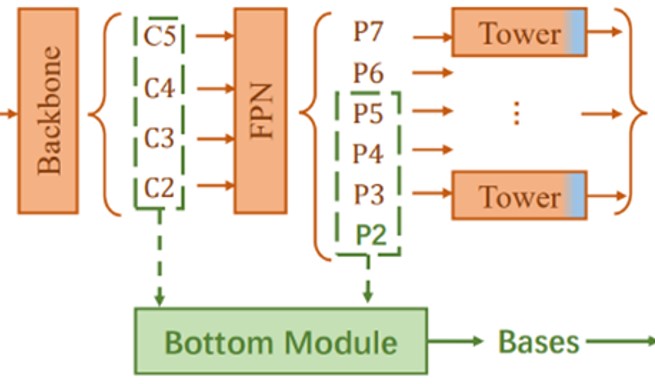
- 用于预测 prototype mask,论文中称这个为Base(B)。输入的维度为 (N, K, H/s, W/s)。
- N为batch size, K为Base的数量(4),H和W是输入图像的大小,s则是Base的输出步长。
-
Attention Module:
模型包含注意力模块,用于对特定区域进行加权,使网络能够集中关注对实例分割特别重要的区域。这有助于提高模型在复杂场景中的性能。
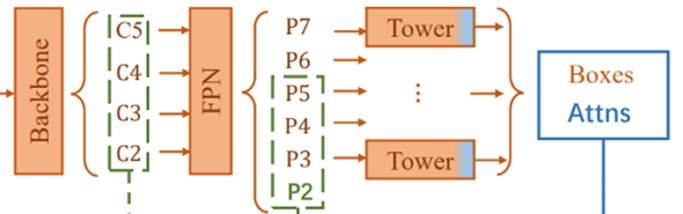

-
Instance Head:
BlendMask 使用实例头(Instance Head)来预测每个目标实例的类别、边界框和实例分割掩膜。这使得模型能够同时执行目标检测和实例分割任务。
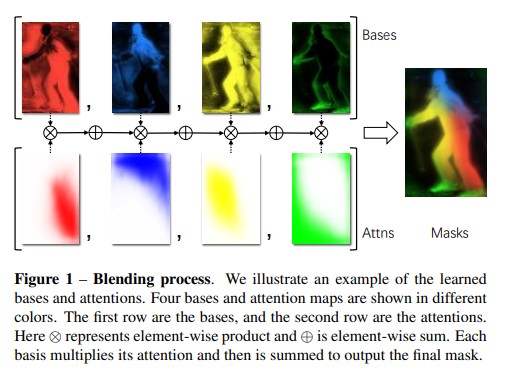
- detector tower 生成的bbox proposal(P),维度为(K×H’×W’);此外,在训练的时候,直接使用GT bbox作为P,而在推理时,则使用检测器的检测结果。
- top layer 生成的top-level attention(A),维度为(K×M×M)
- bottom module 生成的base(B),是整图大小的k个mask,维度为(K×H×W)
具体得到Instance Head的过程: - 对B:使用Mask R-CNN中的RoIPooler(即sampling ratio 为1 的 RoIAlign,Mask R-CNN中为4),在 B 上crop出 P 对应的区域的mask,并resize到固定R×R大小的特征图 ,最后得到的 rd的维度为(K×R×R);(K, R 分別在论文设置为 4 和 56)
- 对A:这一步其实是top layer中的后处理操作。作者根据FCOS中的后处理方法,选出前D个检测框和对应的A,并通过RoIAlign (sampling ratio=1) 和 reshape,将A的维度由(K*M*M, H‘, W’)调整为(K×M×M),记为a;
- 对a:由于M一般小于R,做一个插值,将 A 从 M×M 插成 R×R 大小,得到的 ad 维度为(K×R×R),再在K维度上做softmax,得到一系列的scores map,sd的维度同样为(K×R×R)
- 这时的 rd和 sd都是 (K×R×R) 的大小,可以直接做element-wise product:把k个bbox大小的mask和对应的attention乘起来,再按通道叠加起来,得到最终的mask
-
Loss Function:
模型使用多任务损失函数,包括目标类别损失、目标边界框损失和实例分割掩膜损失。这些损失函数共同训练模型,使其能够在多方面取得优异的性能。
BlendMask 的特点:
-
高级别特征融合:
BlendMask 充分利用主干网络和特征金字塔网络,实现高级别特征的有效融合,提高对目标的抽象和表征能力。
-
上下文感知和注意力机制:
引入上下文模块和注意力模块,使模型具有更强的上下文感知能力和对重要区域的关注能力,有助于提高实例分割的精度。
-
多任务学习:
BlendMask 通过多任务学习,同时进行目标检测和实例分割,使得模型在不同场景下更全面地理解图像内容。
发表回复