最近,Meta 发布了最新的 LLaMA 3。我这边利用 ollama + Open WebUI 来实现大语言模型的本地部署。
Ollama 安装
我按照 GitHub 上的 manual install instructions下载程序并赋予权限:
sudo curl -L https://ollama.com/download/ollama-linux-amd64 -o /usr/bin/ollama
sudo chmod +x /usr/bin/ollama
我并没有安装说明的那样专门创建一个运行 ollama 的用户,依然使用我本身的用户名。
创建服务文件
我创建了服务文件 /etc/systemd/system/ollama.service:
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/bin/ollama serve
User=alex
Group=alex
Restart=always
RestartSec=3
Environment="OLLAMA_HOST=0.0.0.0"
[Install]
WantedBy=default.target
注:我这里与说明里面有一点点小的区别,主要原因在 FAQ 里面有提及:
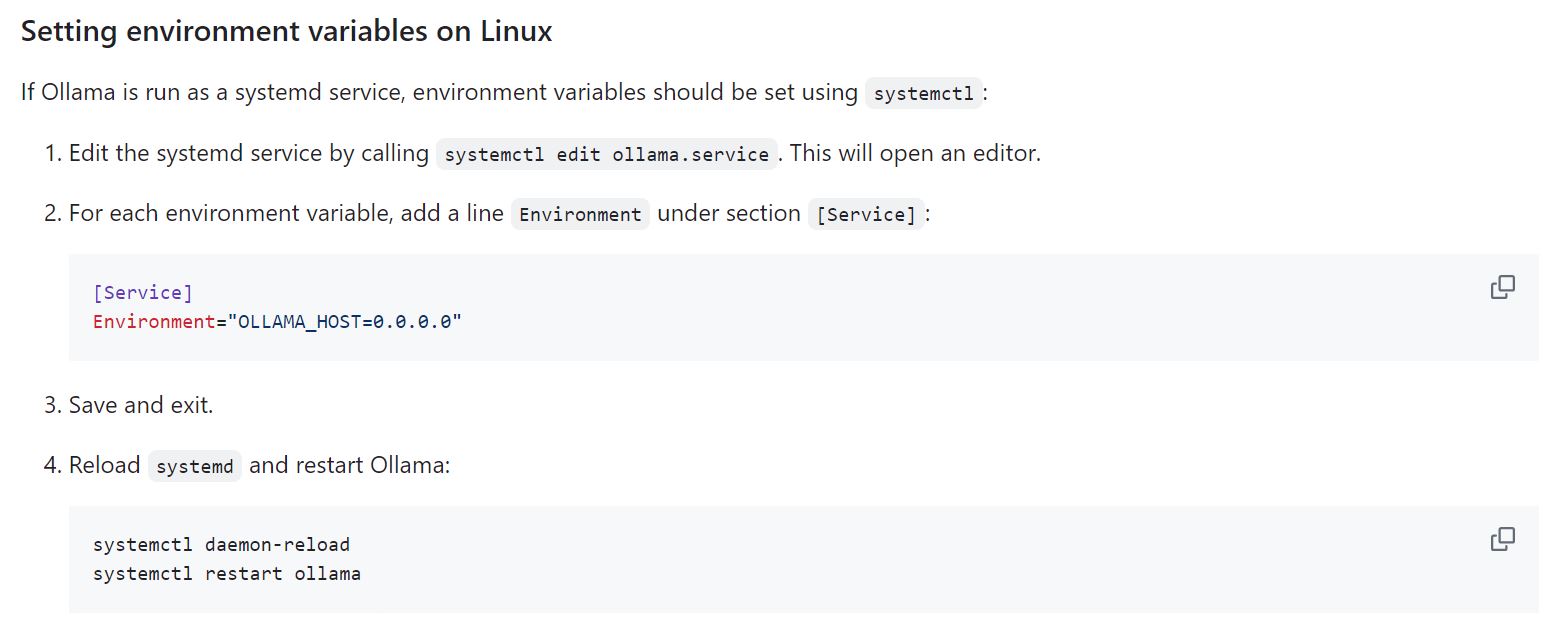
CUDA 安装
考虑我已经安装过 NVIDIA 的驱动以及 CUDA 了,所以这部分我们省略下,网上很多这方面的教程。
运行 Ollama 服务
我启动了 ollama 服务:
sudo systemctl start ollama
从然后开始,每次启动都会自动运行。
基本使用
安装完成后,基本使用是:
ollama run llama3
这将自动下载所需的模型。然后你可以直接使用它,但是使用方法有点不便捷,主要在命令行形式。

Open WebUI
为了使其更加用户友好,我使用 Open WebUI 作为交互接口。在 fact,ollama 的 GitHub 也引入了其他的 UI 方法,我选择了第一个。
我使用 Docker 安装了 Open WebUI:
docker run -d -p 3000:80 -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
安装完成后,你可以通过 http://localhost:3000 访问它。使用方法类似于 ChatGPT,简单易用。
注意
整个方案需要使用计算机 HTTP 端口 3000(外部)、8080(Open WebUI Docker)和 11434(ollama 服务)。你需要在安装前确保这些端口未被占用。
发表回复