最近客户遇到一个Unet分割模型,在量化以后精度下降比较明显。如同正常我们遇到精度问题一样,一般从几个点出发:
- 使用更高级的optimization level 尝试看看精度是否提高,测试结果有提高但是整体还是比较差
- 利用 “quantization_param(output_layer1, precision_mode=a16_w16)” 将输出结果设置为16bit量化,查看结果依然不理想。
- 我们也利用 analyze-noise 查看SNR, 大体上SNR虽然不算太高,但是也在20左右。
在没有办法的情况下,我们尝试了将所有的量化使用16 bit 量化查看(model_optimization_config(compression_params, auto_16bit_weights_ratio=1)), 发现精度正常了。注:此方式不适合所有的模型,仅仅适合一些相对比较简单的模型。
在这种情况下,我们注意到了模型结尾附近 Concat6之后的SNR相对低一些。
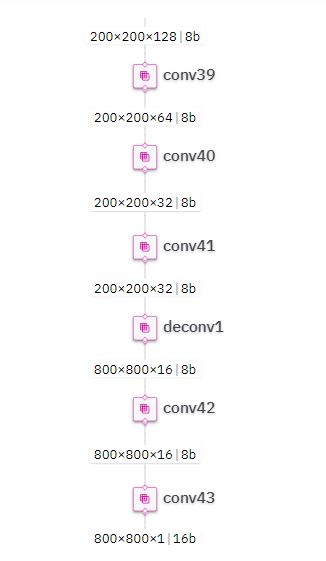
我们尝试将这些节点全部设置为16bits量化:
- quantization_param(deltaq_unet_pcv_shape800x800/conv40, precision_mode=a16_w16)
- quantization_param(deltaq_unet_pcv_shape800x800/conv41, precision_mode=a16_w16)
- quantization_param(deltaq_unet_pcv_shape800x800/deconv1, precision_mode=a16_w16)
- quantization_param(deltaq_unet_pcv_shape800x800/conv42, precision_mode=a16_w16)
- quantization_param(deltaq_unet_pcv_shape800x800/conv43, precision_mode=a16_w16)
通过一点点的实现对比,最终只需要将节点deconv1 16bits量化就可以达到不错的精度了。虽然最终性能比全8bit略微差一些,但是这种方式能基本保证分割模型的量化精度,也算不错的折中方案了。
发表回复