最近做了一个人脸检测模型 SCRFD10g 的 Demo,该模型的 GitHub 地址是 SCRFD。在该 Demo 中,除了检测人脸外,还将人脸坐标 10 个值显示出来,包括 5 个点、2 个眼睛、鼻尖和 2 个嘴角。
重点关注此模型的 NMS 后处理部分,特别是此模型在 Hailo 平台中运行的时候后处理部分。可以通过 hailortcli parse-hef scrfd10g.hef 查看此模型的输出节点。
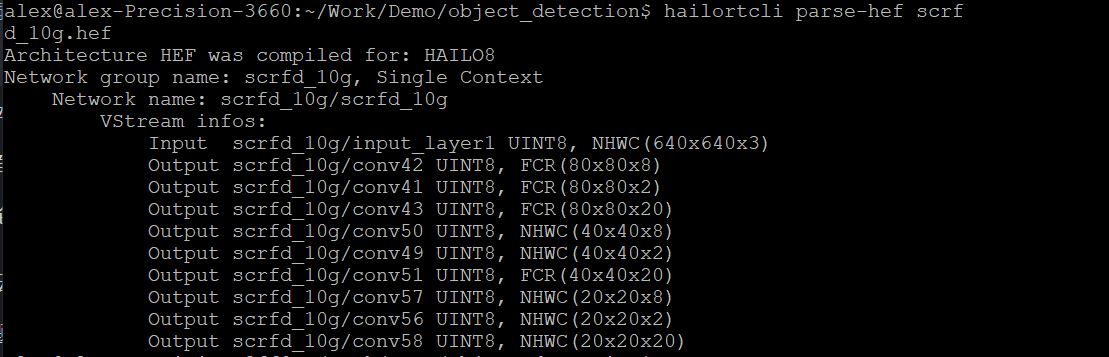
明显地,模型与 YOLO 有着类似的 anchor 输出,特征图也是一样的 20×20、40×40 和 80×80。其中:
- scrfd_10g/conv42、scrfd_10g/conv50、scrfd_10g/conv57 为 2 个 anchor 的框坐标。
- scrfd_10g/conv41、scrfd_10g/conv49、scrfd_10g/conv56 为 2 个 anchor 的置信度值。
- scrfd_10g/conv43、scrfd_10g/conv51、scrfd_10g/conv58 为 2 个 anchor 的关键点坐标。
类似 YOLO 的后处理,我们将 9 个输出口按照特征图进行分 3 组,每组里面有分 3 类处理:置信度、解码框、解码关键点。这里我们先通过函数 scrfd_conf_processing 通过特征图区分,将反量化后的置信度全部得到并依赖阈值来筛选我们需要处理的索引(保存具体特征图的宽度、高度和 anchor 值)。
第二步,我们通过前面得到的索引,去框组,通过 decodeBox 得到框值:
float centor_x = (float)col/map_size;
float centor_y = (float)row/map_size;
float scale = (float)1/map_size;
float x1 = centor_x - boxDetection[0] * scale;
float y1 = centor_y - boxDetection[1] * scale;
float x2 = centor_x + boxDetection[2] * scale;
float y2 = centor_y + boxDetection[3] * scale;同样的原理,我们可以通过 decodeLandmark 计算出 5 个点的关键点坐标:
for (int i = 0; i < NUM_LANDMARKS; i += 2) {
x1 = centor_x + landmarkDetection[i] * scale;
y1 = centor_y + landmarkDetection[i+1] * scale;
}最后,将得到的超过阈值的所有坐标做一次 IOU 筛选,就可以得到我们最终希望得到的坐标结果了。
整个来看,SCRFD 的后处理还是挺简单的,因为其只有一个 face 类别,不像 YOLO 一样有 80 个类别,并且其输出口将置信度、框以及关键点拆分出来分别输出,而没有合并在一起需要自行组合。再次其通过中心点与 scale 得到框和关键点的方式也非常简单,直接做一次中心点加减运算即可。
发表回复