YOLACT 架构与特点
YOLACT(You Only Look At CoefficienTs)是一种用于实例分割的目标检测模型,具有创新的架构。以下是 YOLACT 架构的简要介绍:
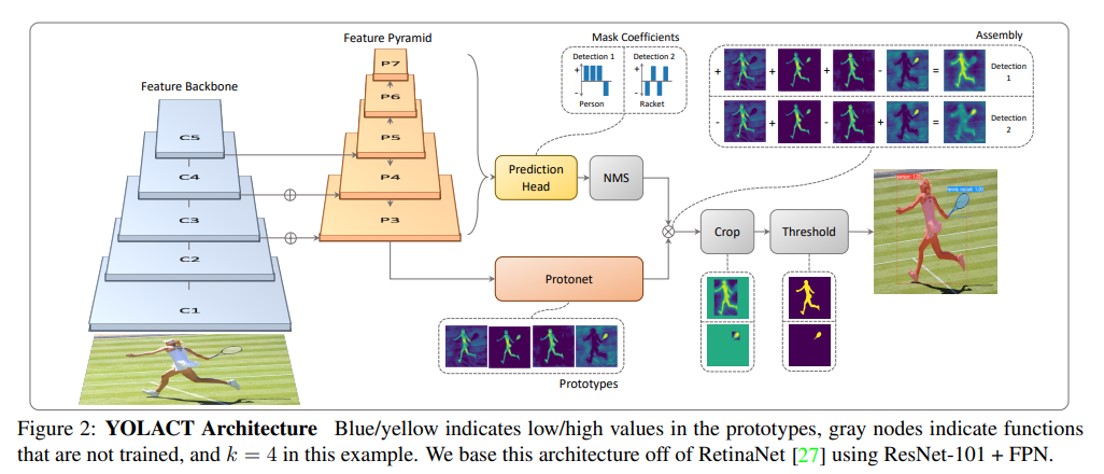
-
主干网络(Backbone):
YOLACT 使用一种强大的主干网络(backbone network)来提取图像特征。通常采用的是 ResNet 或者 ResNeXt 这样的卷积神经网络作为主干网络。这个主干网络负责从输入图像中提取高级别的特征,以便后续的任务处理。
-
FPN(Feature Pyramid Network):
YOLACT 引入了特征金字塔网络(FPN),用于处理不同尺度上的目标。FPN 通过在不同层级上建立特征金字塔,使模型能够在不同尺度上检测目标,提高了对小目标和远处目标的检测能力。
-
CoefNet:
YOLACT 的核心是 “CoefNet”,即线性组合系数网络。这个网络学习并预测用于实例分割的线性组合系数。这些系数被用来计算目标实例的原型(prototype)特征,从而表示目标的共享特征。
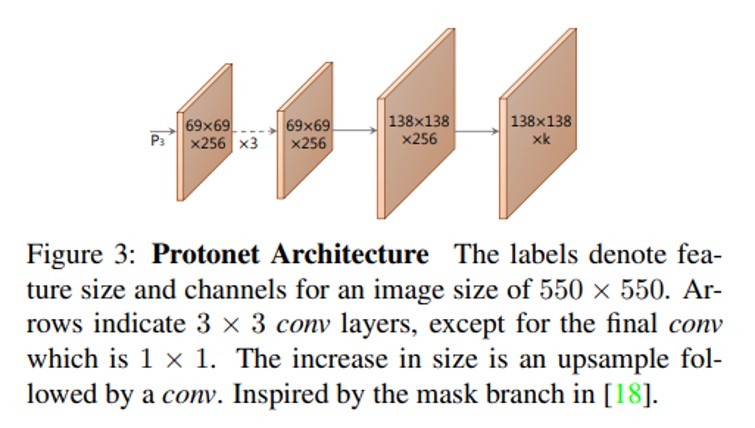
- 用于预测质量更高的prototype mask,为了能更好的预测小物体。其输入是采用 FPN 的 P3,输出 mask 维度为 138x138x32 (k 预设值为 32)。
- 图中18指的是 Mask RCNN
-
Prototype Masks:
YOLACT 使用学习到的系数结合原型特征生成每个目标实例的原型掩膜。这些原型掩膜被用于表示目标的形状信息,实现实例分割。
-
预测头(Prediction Heads):
YOLACT 包含多个预测头,分别用于输出目标的类别、边界框和掩膜信息。这些预测头一起构成了 YOLACT 的综合输出,实现了目标检测和实例分割任务。
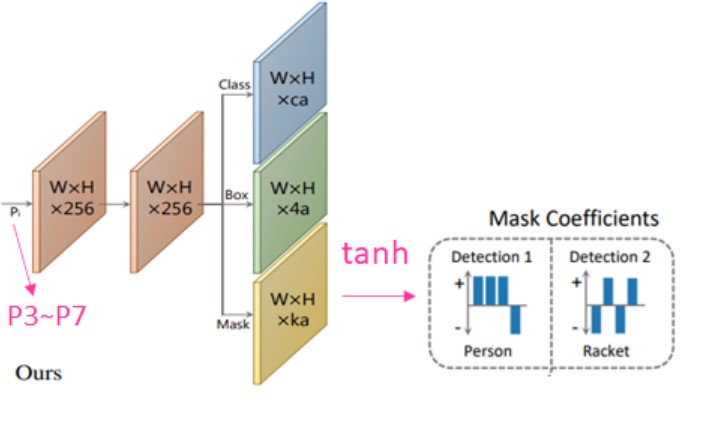
其输入是 FPN 的 P3~P7,输出为三项: class, bndBox, Mask Coefficients,其中 Mask Coefficients 用于 prototype mask (Protonet 输出,原型 mask) 进行加权。
此外,为了更好地和 prototype mask 融合,会先对 Mask Coefficients 进行tanh,使其值更加稳定。
其中k为32(预设值), a为所有的P3~P7 的anchor 数量。 -
损失函数:
YOLACT 使用多任务损失函数,包括目标类别损失、目标边界框损失和实例分割掩膜损失。这些损失函数共同训练模型,使其能够在综合任务中取得良好的性能。
-
汇总形成分割结果
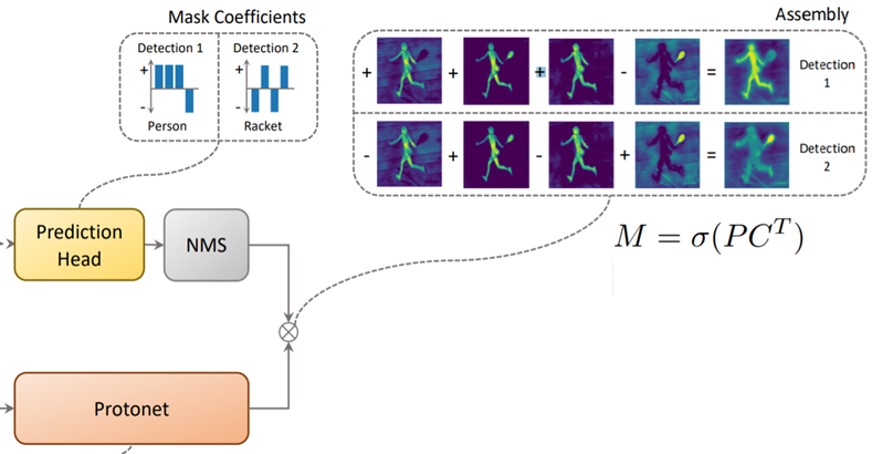
- 将prototype mask 与 Fast NMS 后的 Mask Coefficients 进行组合得到最终的Mask
- 在 FPN 的 input feature map (P3~P7) 中每个grid 会生成 3 个 Anchor,每个 Anchor 面积都是相同尺寸,分別为 [24, 48, 96, 192, 384],其长宽比 (aspect ratios) 会根据 1:1、1:2、2:1 比例调整。
优点
-
快速速度:
YOLACT 是一种单阶段(one-stage)目标检测模型,其预测过程是一个矩阵操作,因此具有较快的推理速度。
-
高质量的实例分割:
YOLACT 使用生成原型掩膜和系数的思路,能够生成高质量的实例分割掩膜。通过利用共享特征和线性组合,实现了对目标的准确表示。
-
普适性强:
YOLACT 的思路可以应用于许多流行的检测器,这使得其在不同任务和场景中具有较强的适应性。
缺陷
-
性能相对较低:
在2020年,YOLACT 的性能相对较低,尤其在实例分割任务的准确率上表现不如一些其他先进的实例分割方法。
-
实时性和准确率兼并的挑战:
大多数任务需要实时性和准确率的兼并,而 YOLACT 的性能可能在这方面存在一些挑战。
发表回复